

本文主要介绍守护星数据库监控这个产品(简称AG),从以下5个方面进行介绍:
|
一 |
运维痛点 |
|
二 |
新型运维模式 |
|
三 |
产品功能介绍 |
|
四 |
应用场景 |
|
五 |
安装部署 |
一、 运维痛点
目前IT行业面临的运维痛点主要是以下5点:

二、新型运维模式
接下来详细了解一下传统运维模式和新型运维模式之间的对比和差异:
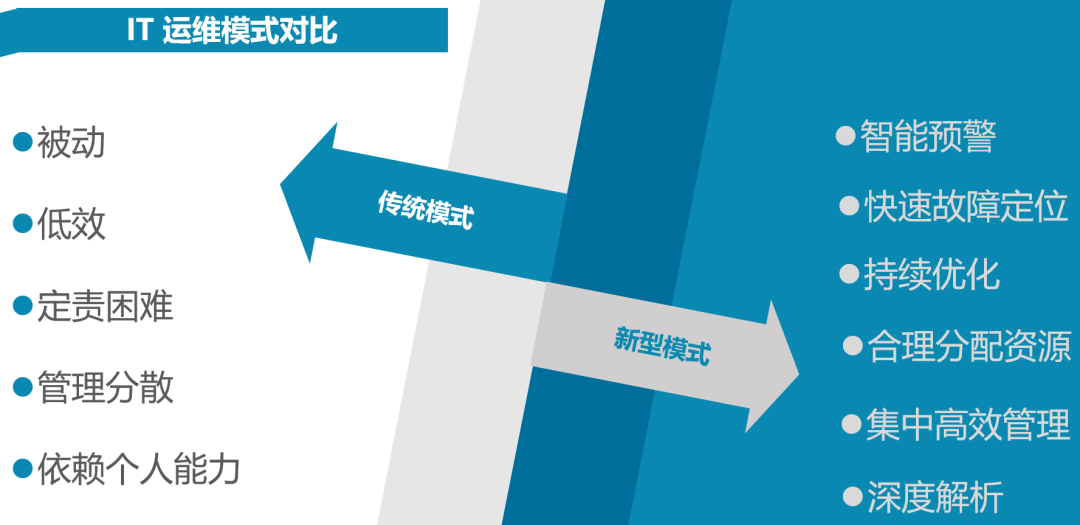
可以看到,传统模式有如下弱点:被动、低效、定责困难、管理分散、高度依赖个人能力;而新型模式中,通过智能预警、快速故障定位、持续优化、合理分配资源、集中高效管理、深度监控数据解析等手段,去改善、优化传统模式中的不足,以提高IT运维的服务支撑能力。
三、产品介绍
以上内容简单阐述了IT运维工作中的痛点,以及新型运维模式所具备的特征,那么新型模式该怎么实现呢?又需要借助哪些手段呢?
下面我们从数据库运维管理的维度出发,围绕如何实现新型运维模式,介绍一下产品应该具备哪些关键功能。
01 完善的监控预警手段
首先,监控系统的一个重要职责,也是核心功能——预警。好的预警可以帮助用户及时发现问题,并通过合适的手段,如短信、邮件、大屏等方式,将告警信息推送至相关的负责人。
短信和邮件等即时消息,立足于“随时随地”掌握系统运行状态,因而其必要性不言而喻。而大屏则是着重于更全面、更易懂的初衷,帮助用户建立对系统全局健康度的总览。下面是两个不同维度设计的大屏:
基于异常事件处理进度的大屏

基于详细数据库运行指标的大屏
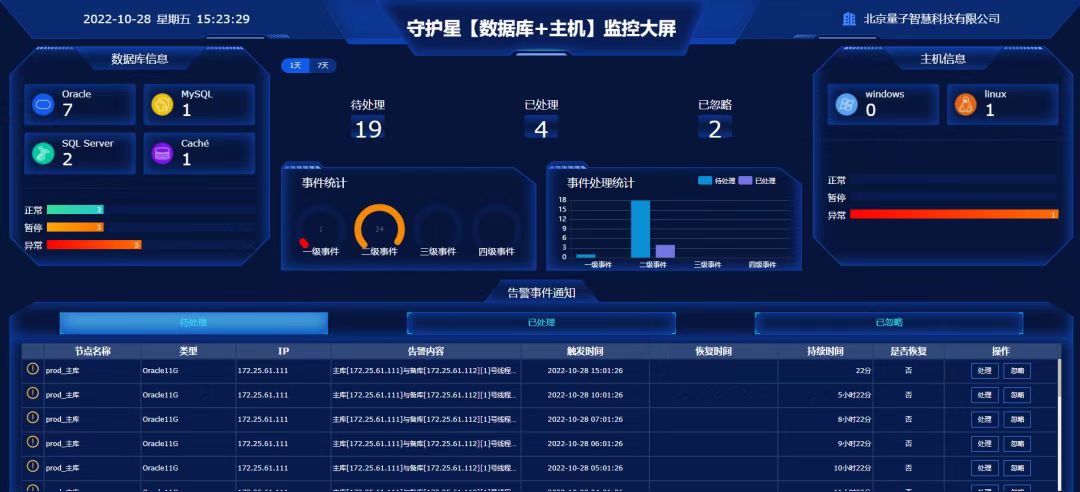
“基于异常事件处理进度的大屏”主要是帮助用户建立告警事件闭环管理,目的是让预警“有始有终”、“落到实处”。而"基于详细数据库运行指标的大屏"则目的在于为用户提供更为直观和丰富的数据运行关键指标,更有助于快捷的分析和判断问题。
02 便捷、高效的故障诊断
我们都知道,仅有告警是不够的,如何能够让告警接收人快速的实现故障诊断和定位,则更加有助于进一步提升运维工作价值。
守护星提供了三大类诊断功能,分别是“历史问题诊断”、“实时问题诊断”、“问题链诊断”。
其中“历史问题诊断”通过【历史性能分析】的数据库开销曲线图(类似于将Oracle AWR报告图形化),识别到异常峰值,进而定位过去的某个问题发生区域。
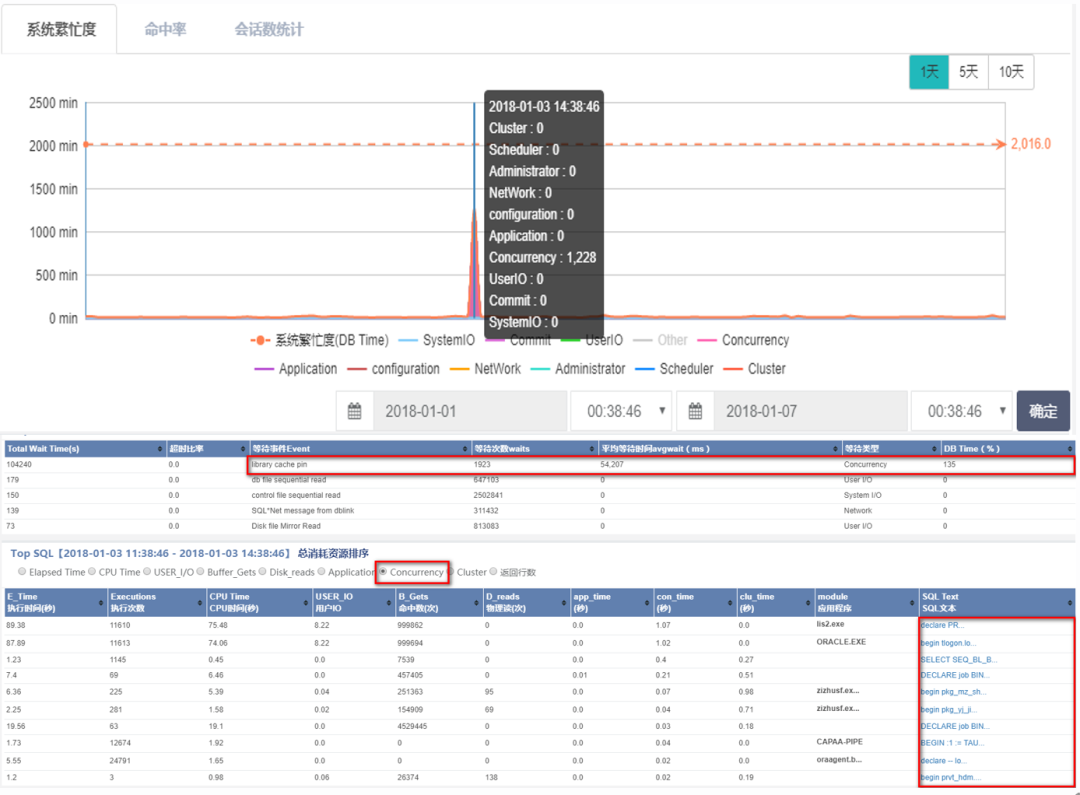
历史问题诊断功能示例图
“实时问题诊断”则是借助“工具箱”实现,工具箱包括各种常用的问题诊断按钮,也能够生成相关的问题分析报告,来帮助用户诊断正在发生的问题。
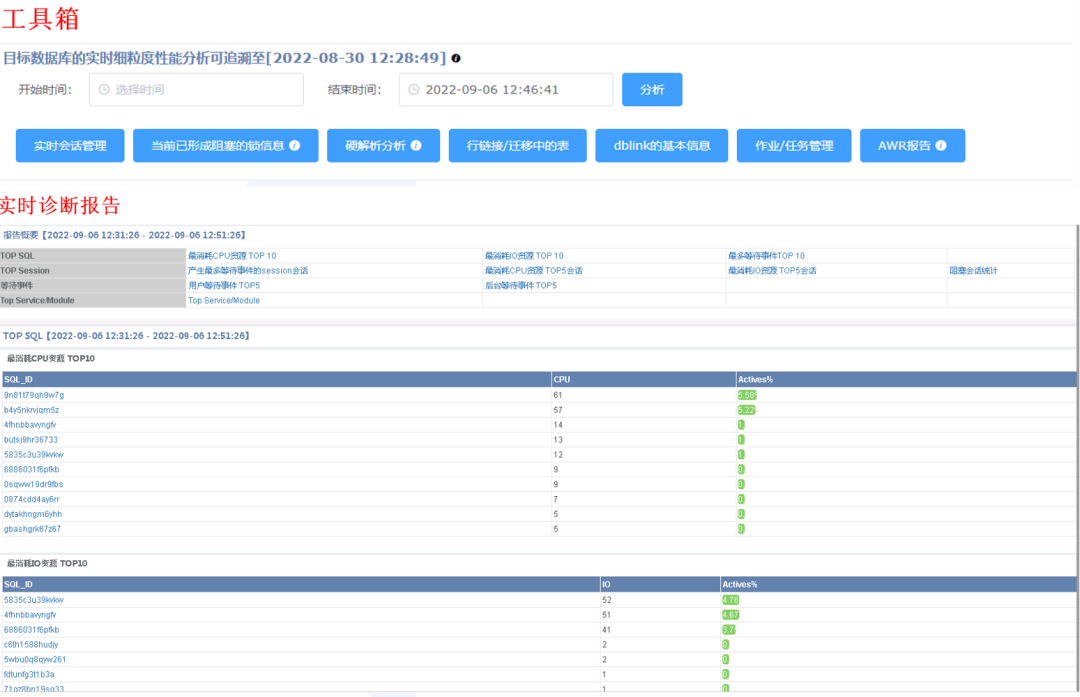
实时问题诊断功能示例图
“问题链诊断”是指当问题发生时,不仅仅发出预警信息,同时采集当时的关键指标信息,用于辅助报警的分析和诊断,大幅度提升问题实时定位的效率。此外,这些指标还会进行归类并存放于后台表中,可以用于后期进行问题复盘分析。
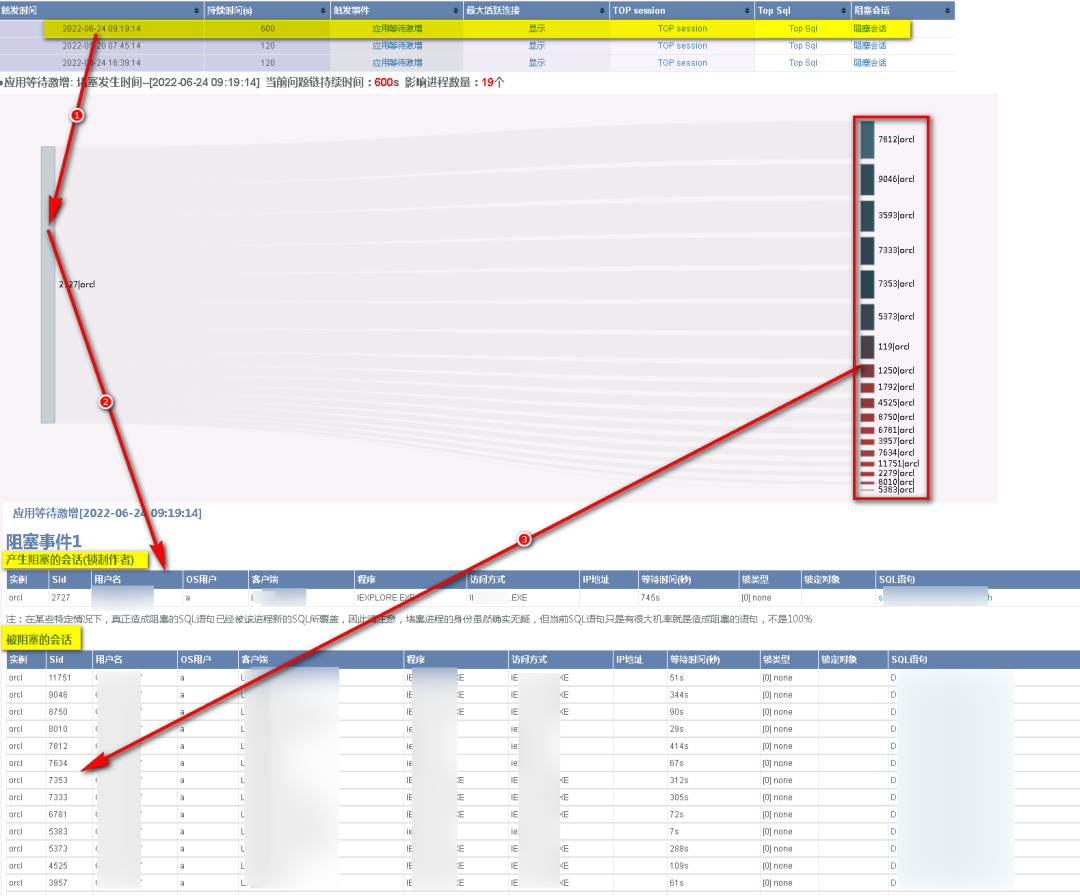
问题链诊断功能示例图
03 持续的性能监测和跟踪
接下来要解决的是性能优化的问题。性能优化是IT运维工作中的一项持续周期非常长的工作内容,通常来讲贯穿于系统的全生命周期。因而其工作势必不可能是一日或者数日之功,如何建立长期的性能检测,如何实现持续不断地主动式性能优化,则是区别于传统运维中慢了再治的标准。
如下图所示,是基于可监测指标实现的“监控——优化”增强回路,实现监测与优化互相促进,迭代进步的效果:

持续监控与优化的增强回路
下面展示一个使用历史性能数据,实现优化,以及优化前后对比的例子:
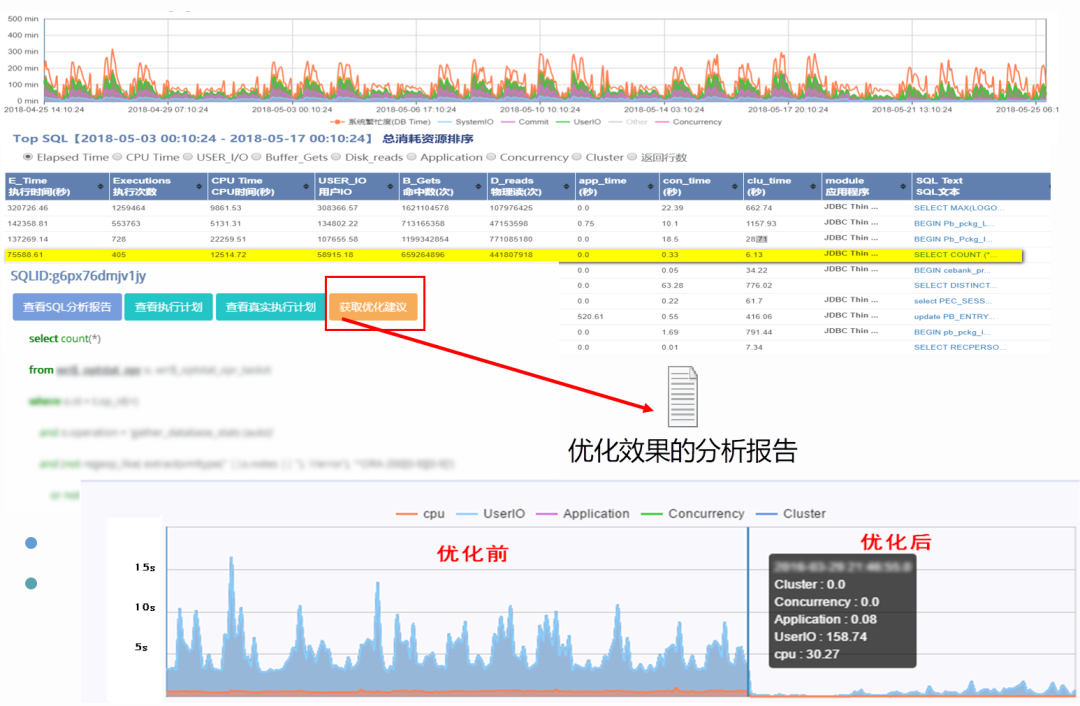
性能优化案例图
上图中,首先通过历史性能趋势分析,定位异常峰值,接着定位异常语句,进而获取优化建议,最后再通过SQL开销趋势图,实现优化前后的性能开销对比。
在这个过程中,优化建议可以是通过程序自动获取,也可以是管理员通过获取执行计划、真实执行计划等信息,经过分析后给出的优化建议。一般情况下,我们建议管理员通过分析执行计划的方式,去优化SQL。
04 日常巡检
这一部分主要讲巡检功能,巡检作为一项重要的日常运维工作内容,具有很实际的意义,例如发现隐患、资源合理规划等等。
守护星中提供两种巡检模板,分别是单库巡检和多库巡检。
顾名思义,单库巡检就是每次巡检一个库,其主要解决的是单个数据库的详细指标巡检,包括基本信息、表空间、性能指标、高耗时SQL等一系列信息的集中呈现。如图中所示,是某个数据库生成一份详细的单库巡检报告。
而多库巡检则面向同时巡检多个数据库,目前支持的指标较少,仅包括表空间、ASM空间、磁盘空间、备份作业等。
如下图所示,为单库巡检结果的示例:
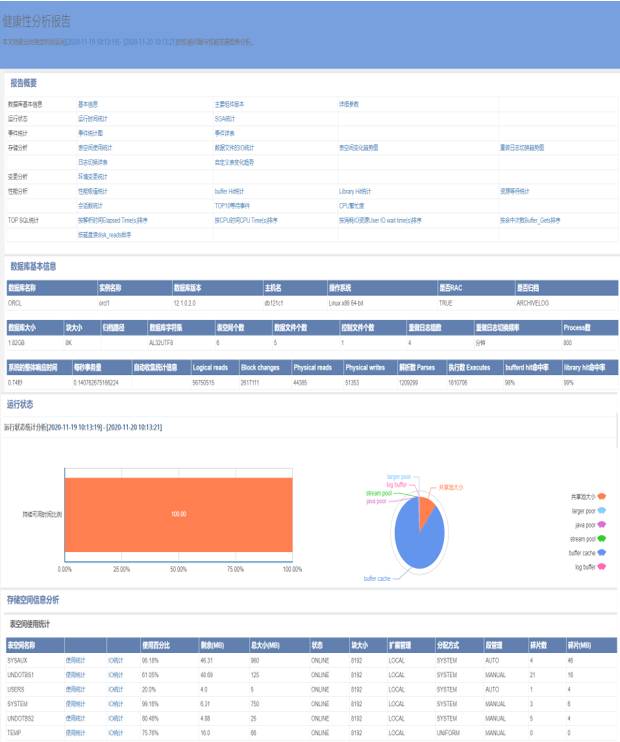
单库巡检结果图
05 主机监控
为了更好的实现对数据库的立体化监控,我们引入了主机监控,实现了对一些关键的主机监控指标的监测。
主机监控功能主要支持Linux、AIX、Unix和Windows 4种操作系统。支持的主要指标如图中所示:
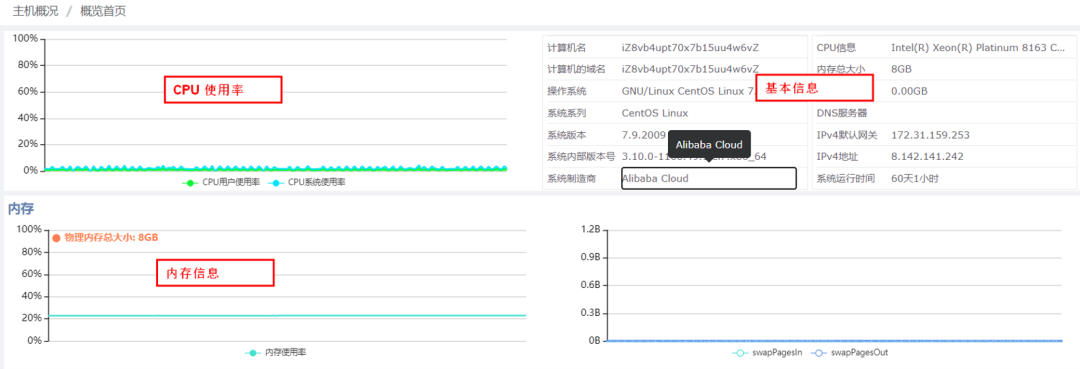
包括基本信息类(如操作系统类型、版本、IP地址、系统运行时间等);
内存类(如内存大小、使用率、交换区大小、换页信息等);
CPU类(如CPU型号、核数、压力等);
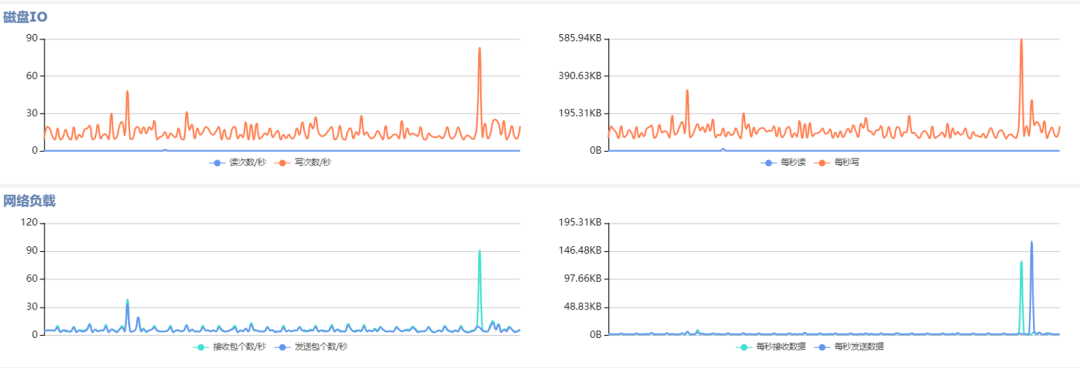
IO类(包括IO速率、IOPS等);
网络类(如网卡信息、网卡流量、机器网络总负载等);

磁盘空间类(文件系统的空间使用率、iNode使用率等)。
四、应用场景
查询库报表数据异常
背景:在过去,Dataguard的备库只是作为实时容灾的备库使用。而随着技术的发展,现在备库可以用来做查询业务了。
现象:但是我们发现有不少突然在某一天发现基于备库的查询库报表数据异常的现象,而后就是排查、解决问题,比较滞后。
原因:这是由于Dataguard的同步状态往往是运维中的盲点,容易被忽略。
一旦主备库的日志同步异常之后,如果长时间未发现,没能解决的话,轻则导致主备库数据差异过大,重则导致主库归档空间满,甚至导致备库需要重建。
方案:因此实现对Dataguard同步状态的监控和预警,对于运维数据库很重要。
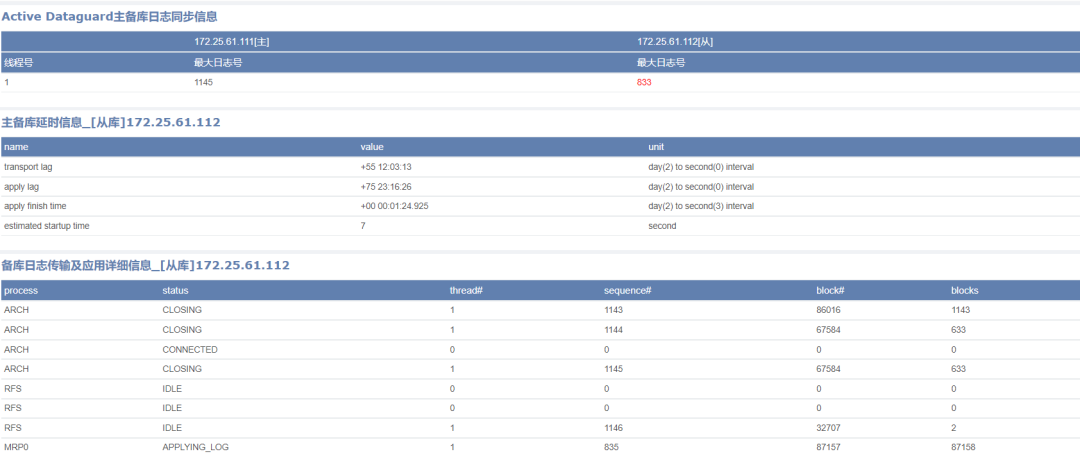
同步异常的Dataguard示例
SQL Server 突发卡顿和IO超时
背景:在实际工作中,数据库默认实施安装之后,部分默认配置可能未调整,导致后期数据库出现异常。
现象:在实际的场景中,可能会突然遇到某些突然发生的业务系统性能问题,比如突发数据库响应很慢。
原因:例如SQL Server 中,数据库文件设置了10%的默认增长,可能引发的日志文件扩增失败导致大面积业务响应超时现象。
方案:对数据库安装配置后,进行例行检查,发现并改正相关的未优化配置即可。
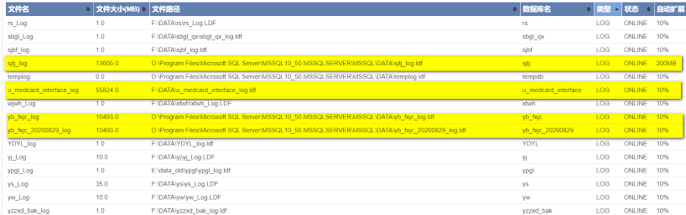
自增属性检查图

自增的趋势图
五、安装部署
最后简单介绍一下产品的安装和部署。其部署的服务器可以是实体机,也可以是虚拟机,甚至于云端部署也可以。
服务器配置需求:64位操作系统,windows 2008或者linux 6以上版本;CPU要求4线程及以上,内存8GB起,硬盘100GB以上。
支持数据库类型:Oracle、SQL Server、MySQL、Cache。
浏览器需求:推荐Edge或者Chrome 90以后的版本。
部署架构:根据用户的节点数量,可以选择分布式部署,或者是单机部署两种方案。